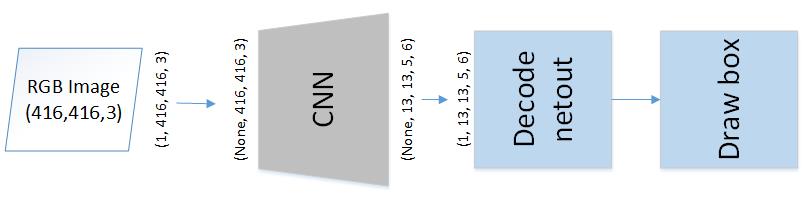
This is a starter implementation of YOLOv2 model for object classification(1 class) and detection using a pretrained weight. My Goal is to detect the Red Blood Cell(RBC) which often involves identifying and characterizing patient blood samples.
Reference:
Datasets download
In RBC_dataset directory, 366 annotations(.xml) are in Annotations directory, and corresponding images(.jpg) in JPECImages
directory. XML files include labelled data in the context of object detection with corresponding bounding box coordinates
and labels.
Ubuntu 16.04.3 LTS
Anaconda3-4.5.11
Cuda v7.5.17
Tesla K40c
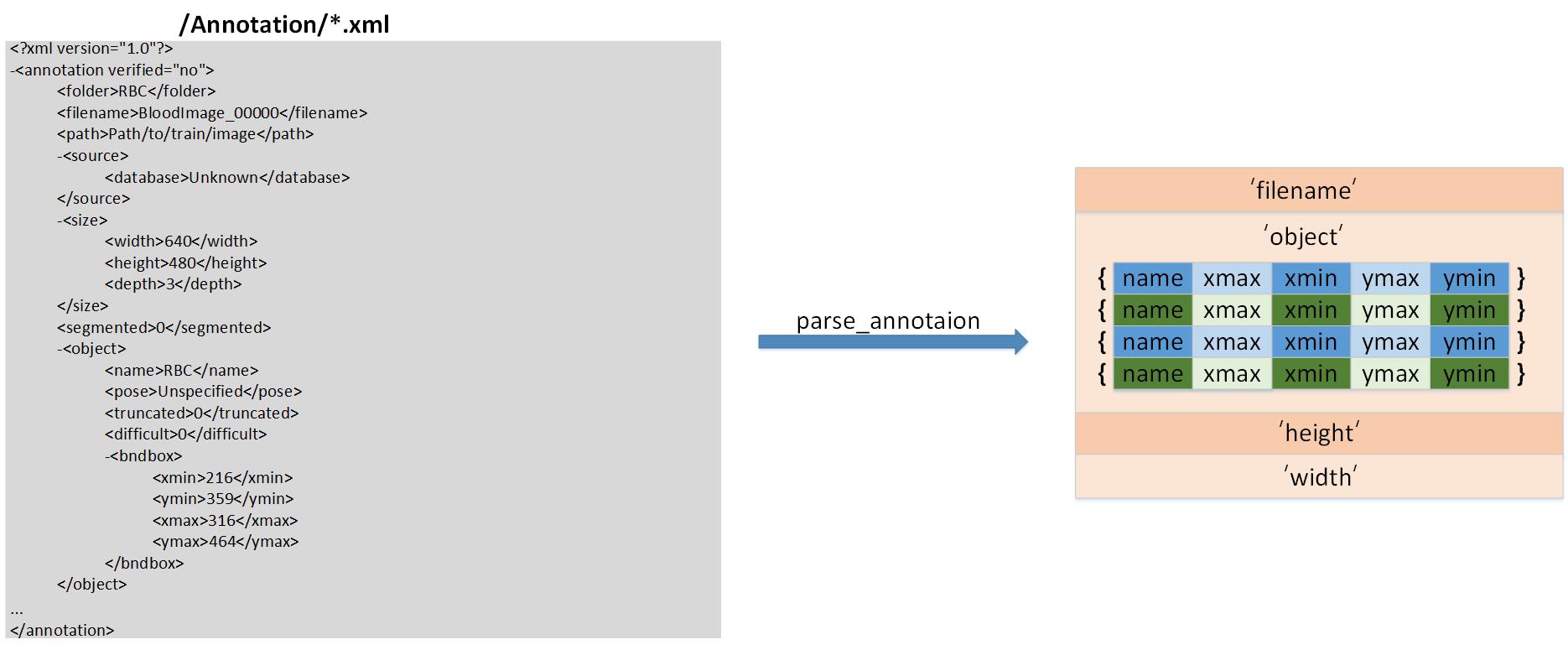
In preprocessing.py, parse_annotation function is to transfer all xmls into a list, and then output 'all_imgs' and 'seen_labels'
to count objects in all classes. parse_annotation transfers the format like :
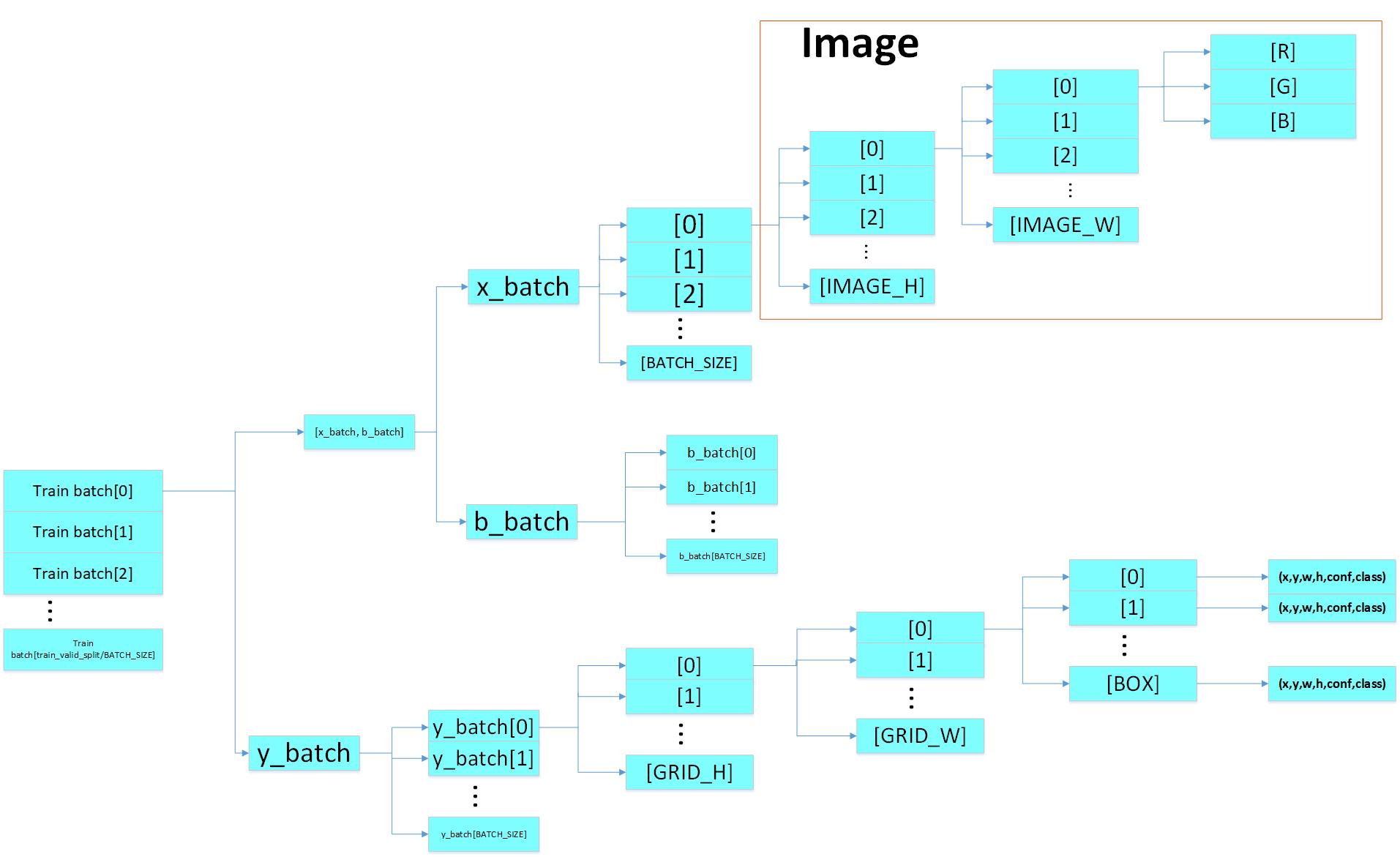
BatchGenerator is a function to suit all YOLO augmentation needs. Its output structure is a multi-dimensional array as shown below. 'x_batch' includes train (RGB) images, and 'y_batch' is the ground truth for calculating loss value. The one-hot encoded 'class' in (x, y, h, w, conf, class) can also express as (x, y, h, w,conf, class0, class1, class2,...) based on how many classes in datasets.
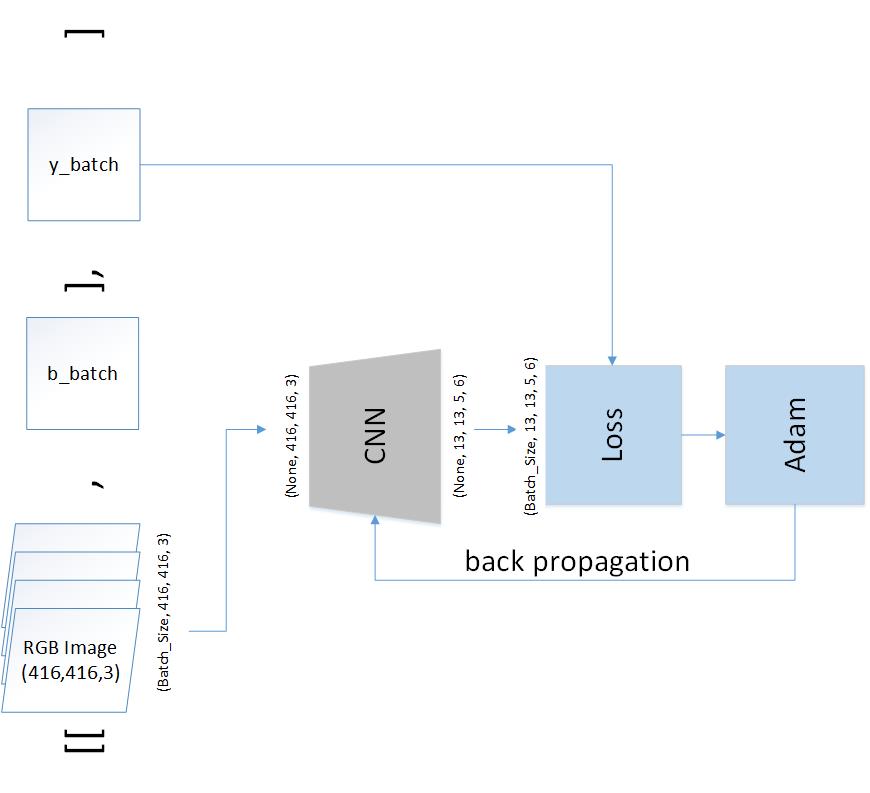
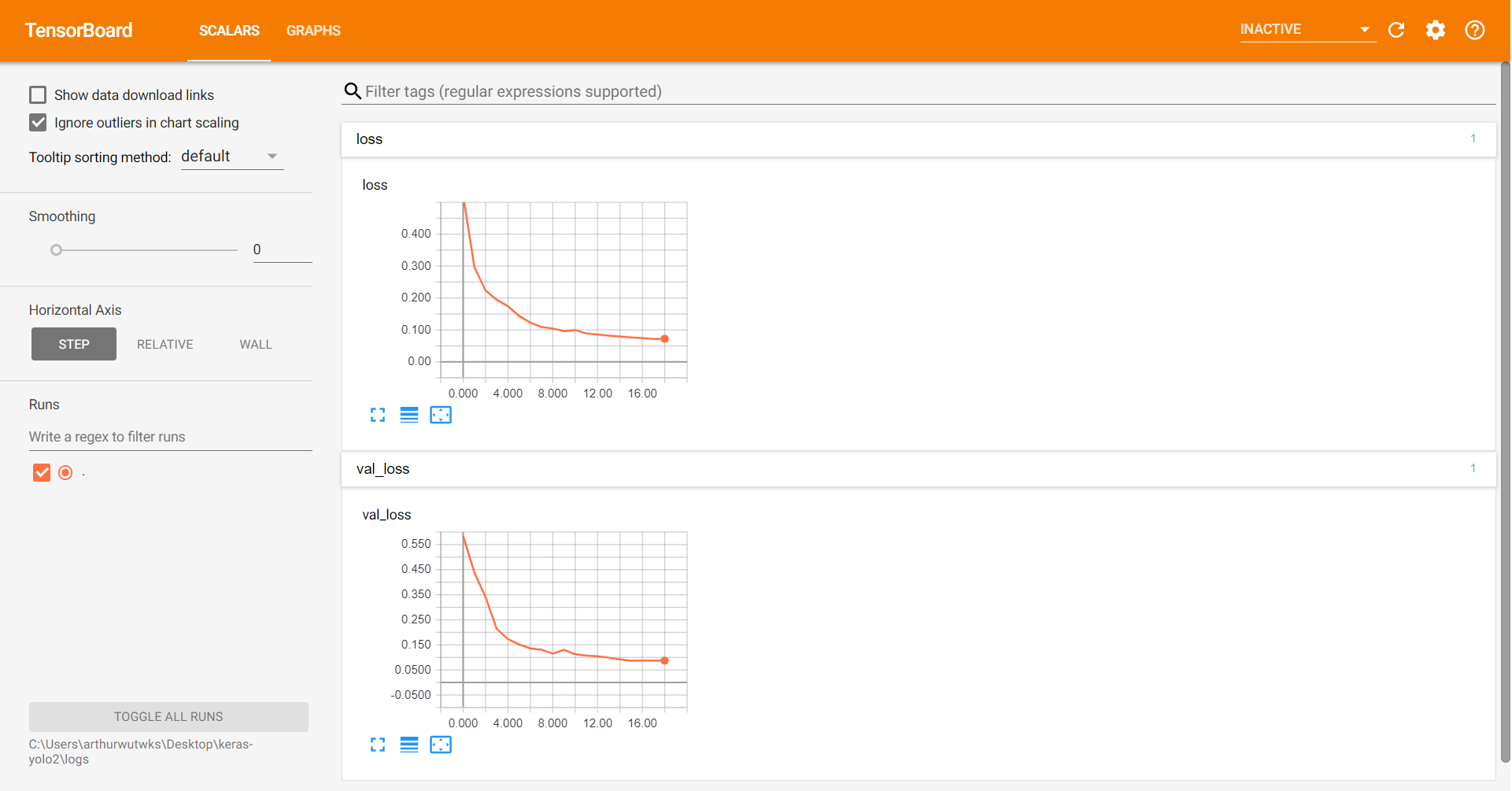
There are total 18 epochs and it stopped because we applied 'EarlyStopping' callback function during my training process. 'EarlyStopping' stops training when the validation data set grows several times.
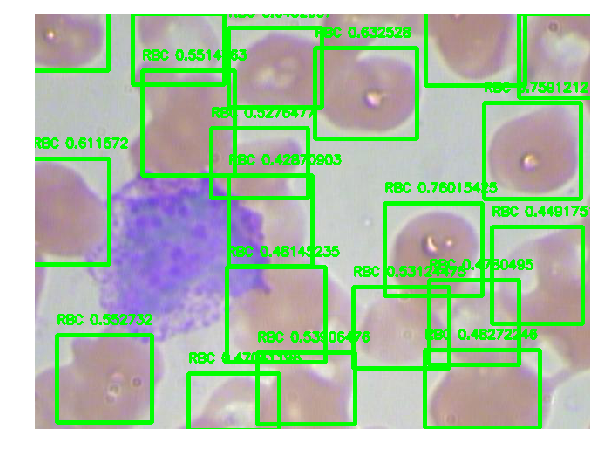
In testing, we fed an (RGB) images as an imput, and obtained a multi-dimensional array(1*13*13*5*6). It contains 13*13 grids, each grid has 5 box candidates, and each box have 6 values (x,y,w,h,p,class). Then, we filtered and removed the box with low probability(5th element p). In the end, draw the bounding boxes to show the object.